


Je voulais apprendre à utiliser des modèles de génération de texte, et leur application dans un contexte de Retrieval Augmented Generation (RAG) m’attirait particulièrement. L’idée est de permettre à un utilisateur de charger ses propres documents, et de poser ensuite des questions auxquelles un modèle de langage (LLM) peut répondre, en s'appuyant directement sur ces documents.
Pour commencer, j’ai décidé de me concentrer sur un format simple : les fichiers PDF (peut-être que les vidéos viendront plus tard ?)
Pour construire rapidement un prototype, j'ai utilisé Streamlit, un package Python qui permet de créer facilement des applications web. L’utilisateur peut ainsi télécharger un PDF, poser une question, et obtenir une réponse générée par l’IA.
Pour la partie intelligence artificielle, j'ai principalement utilisé LangChain, un framework très pratique pour construire des applications utilisant des LLMs. LangChain facilite la connexion à différentes sources de données, la gestion des conversations, de la mémoire, etc.
1. Extraction et préparation du texte
Je commence par extraire tout le texte contenu dans le PDF. Ce texte est ensuite découpé en plusieurs morceaux de taille fixe, appelés "chunks" :
• Chaque chunk fait 500 caractères.
• Les chunks se chevauchent de 100 caractères pour éviter de couper une phrase ou une idée en plein milieu et ainsi perdre du contexte important.
2. Création de l'espace vectoriel
Chaque chunk est transformé en vecteur numérique (appelé embedding), qui capture son sens. Ainsi, deux chunks abordant des thèmes similaires auront des vecteurs proches dans cet espace.
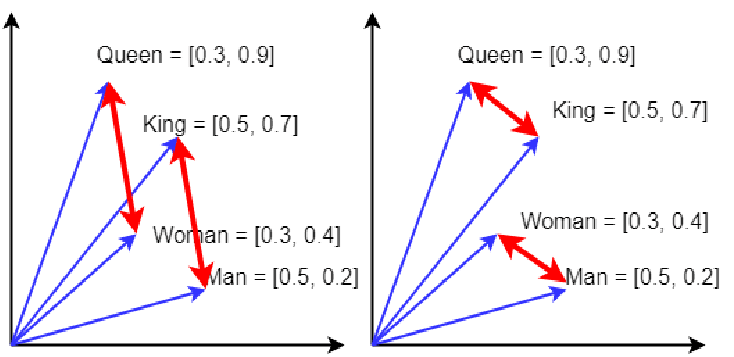
Pour générer ces embeddings, j'utilise le modèle "all-MiniLM-L6-v2" de Hugging Face, via LangChain.
Ensuite, grâce à FAISS (Facebook AI Similarity Search), intégré à LangChain, je construis un espace vectoriel regroupant tous les embeddings.
Cet espace permet ensuite de retrouver rapidement les passages les plus pertinents en fonction de la question posée.
3. Question et génération de la réponse
Lorsqu'une question est posée par l’utilisateur, l’application :
• Cherche dans l’espace vectoriel les chunks les plus proches du sujet de la question.
• Envoie ces chunks en tant que contexte au modèle de langage, accompagnés de la question.
Pour cela, j’utilise un modèle de prompt standard proposé par LangChain :
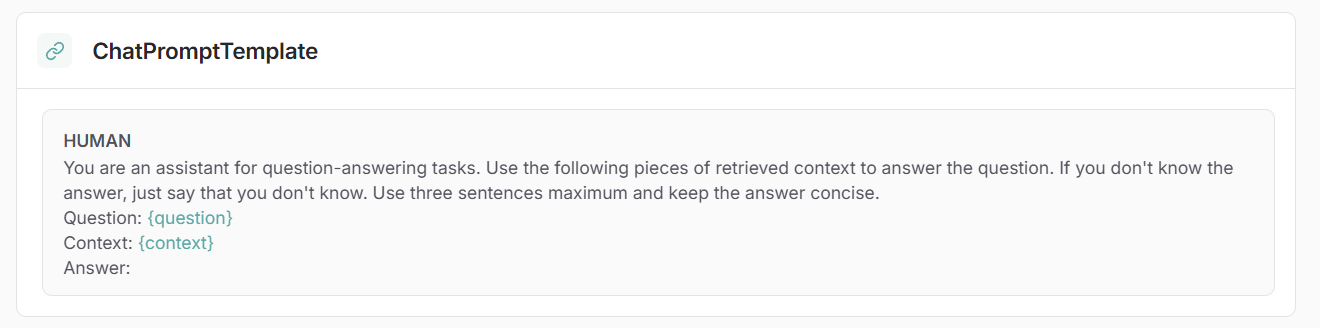
Ce prompt insère automatiquement la question et le contexte avant de les transmettre au LLM, qui génère alors une réponse précise.
Pour simplifier le flux d’opérations, j'ai construit un graphe LangChain qui enchaîne toutes ces étapes automatiquement : de la recherche de contexte à l'appel au modèle de langage.
L’application est alors pleinement fonctionnelle !
Analyser plusieurs fichiers PDF
La première amélioration a été d’autoriser l’analyse de plusieurs fichiers en même temps.
Pour cela :
• J'ai modifié le widget Streamlit pour accepter plusieurs fichiers au téléchargement.
• J’extrais et découpe le texte de chaque fichier individuellement.
• Tous les chunks sont ensuite réunis dans une seule liste pour créer un espace vectoriel global.
Le LLM peut alors répondre à des questions en consultant tous les documents en même temps.
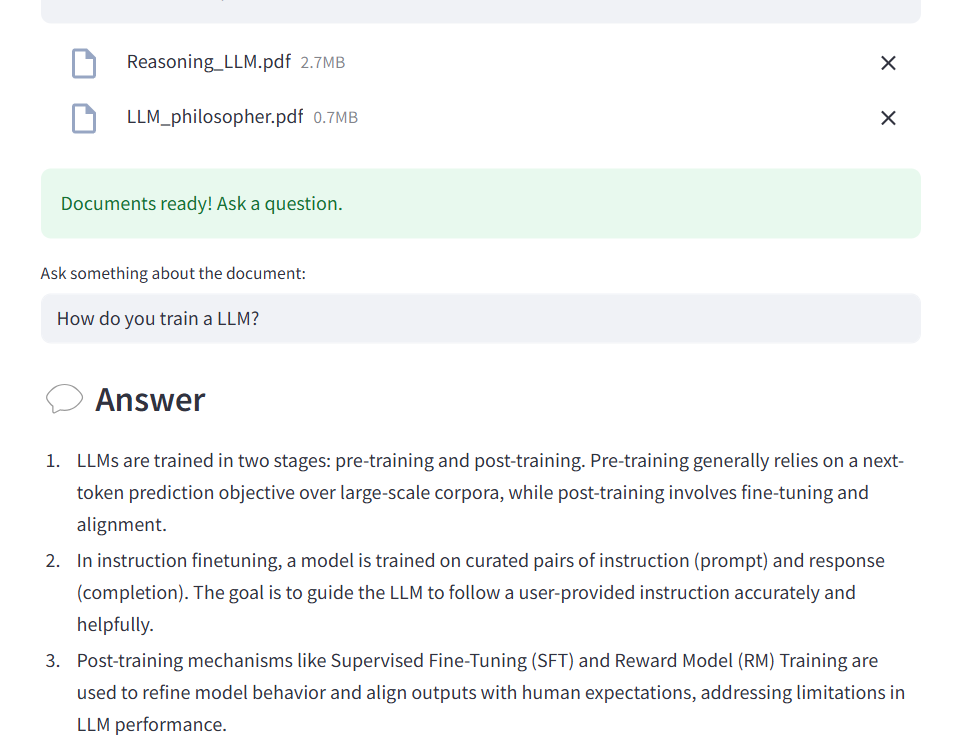
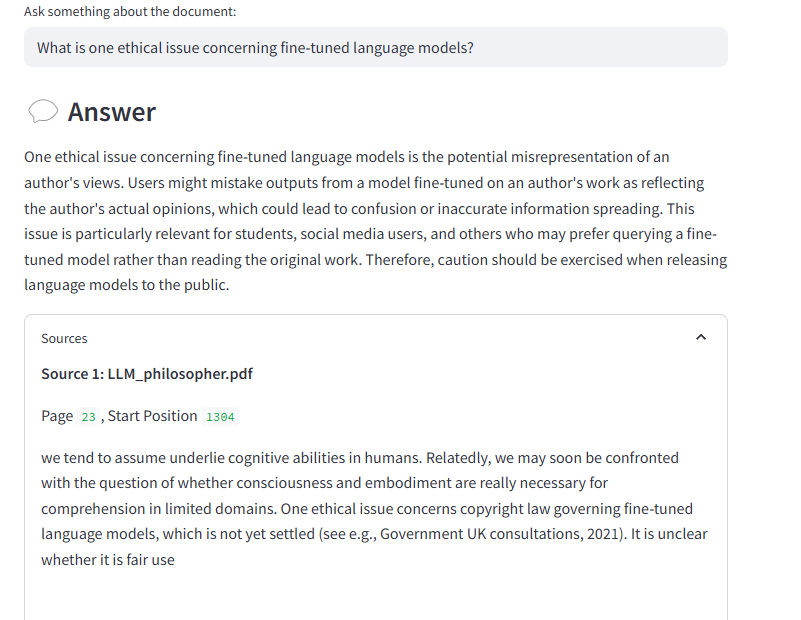
Afficher les sources utilisées pour la réponse
J'ai aussi ajouté une fonctionnalité pour afficher les sources utilisées par le modèle pour formuler sa réponse.
En effet, chaque morceau de contexte extrait est associé :
• Au texte du chunk.
• Au fichier PDF source.
• Et à sa position dans le document.
Après chaque réponse, une section déroulante permet donc à l’utilisateur de lire les extraits précis ayant servi à construire la réponse.

Ce projet m’a permis de comprendre en profondeur comment combiner extraction d’informations, vectorisation et génération de texte pour créer une application interactive.
La prochaine étape sera sûrement d'ajouter de la mémoire au modèle afin de pouvoir créer une conversation, puis d’explorer de nouveaux types de documents, comme des transcriptions de vidéos.